Este post es mi traducción del post A Quick Tutorial on Implementing and Debugging Malloc, Free, Calloc, and Realloc de Dan Luu. Cualquier error o sugerencia sobre la traducción es bienvenida, y si querés que haga de intermediario para sugerirle cambios de contenido a él, también vale.
¡Implementemos nuestro propio malloc y veamos cómo funciona con programas pre-existentes!
Este tutorial asume que sabés qué es un puntero, y que *ptr dereferencia un puntero, y que ptr->foo significa (*ptr).foo, que malloc se usa para reservar (allocar) espacio dinámicamente, y que te es familiar el concepto de lista enlazada. Si decidís seguir este tutorial sin tener un claro conocimiento de C, contame qué partes convendría explicar un poco más. Si querés mirar todo el código de una, está disponible acá.
Presentaciones aparte, la firma de malloc es:
1
| |
Recibe un número de bytes y devuelve un puntero a un bloque de memoria de ese tamaño.
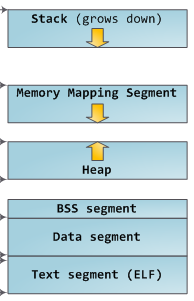
Hay varias formas de implementar esto. Nosotros vamos a elegir arbitrariamente utilizar la llamada al sistema sbrk. El sistema operativo reserva espacios de stack (pila) y heap (montículo) para los procesos, y sbrk nos permite manipular el heap. sbrk(0) devuelve un puntero al tope del heap. sbrk(foo) incrementa el tamaño del heap en foo bytes y devuelve un puntero al tope previo.
Si queremos implementar un malloc realmente simple, podemos hacer algo como:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Cuando un programa le pide espacio a malloc, éste se lo pide a sbrk para incrementar el tamaño del heap, y devuelve un puntero al inicio de la nueva región en el heap. Esta implementación falla en un tecnisismo, dado que malloc(0) debería devolver NULL u otro puntero que se le pueda pasar a free sin romper todo, pero básicamente funciona.
Pero, hablando de free… ¿Cómo funciona? Su prototipo es
1
| |
Cuando le pasan a free un puntero que había sido devuelto por malloc debe liberar ese espacio. Pero si nos dan un puntero a algo reservado por nuestro malloc, no tenemos idea de cuál es el tamaño de ese bloque. ¿Dónde almacenamos eso? Si tuviéramos un malloc funcionando, podríamos mallocear algo de espacio y guardarlo ahí, pero vamos a meternos en muchos problemas si necesitamos llamar a malloc para reservar espacio cada vez que llamamos a malloc para reservar espacio :)
Un truco común para evitar este problema es guardar meta-información sobre la región de memoria en el espacio previo al puntero que devolvemos. Supongamos que el tope del heap actual está en 0x1000 y pedimos 0x400 bytes. Nuestro malloc actual va a pedir 0x400 bytes a sbrk y devolver un puntero a 0x1000. Si, en cambio, guardáramos, digamos, 0x10 bytes para almacenar información sobre el propio bloque, nuestro malloc pediría 0x410 bytes a sbrk y devolvería un puntero a 0x1010, escondiendo nuestro bloque de 0x10 bytes de meta-información del código que está llamando a malloc.
Eso nos permite liberar un bloque, pero… ¿y ahora? Esa región de heap que nos da el SO tiene que ser contigua, entonces no podemos devolverle al SO un pedacito de memoria que esté en el medio. Incluso si quisiéramos copiar todos los datos que están después de la región liberada hacia adelante para rellenar el hueco, cosa de poder liberar el pedazo final del heap, no tenemos forma de actualizar todos los punteros que haya hacia esa zona de memoria a lo largo de todo nuestro programa.
En cambio, podemos marcar que esos bloques fueron liberados sin devolvérselos al SO, y en invocaciones futuras de malloc podríamos reusar esos bloques. Pero para hacer eso necesitamos poder acceder a la meta-información de cada bloque. Hay varias formas de hacerlo, nosotros vamos a elegir arbitrariamente hacerlo con una lista simplemente enlazada por cuestión de simplicidad.
Entonces, para cada bloque, queremos tener algo como:
1 2 3 4 5 6 7 8 | |
Necesitamos saber el tamaño del bloque, si está o no libre, y cuál es el bloque siguiente. Hay también un número mágico ahí (el campo magic) para ayudarnos a debuggear, pero no es realmente necesario. Le vamos a asignar valores arbitrarios que nos van a permitir saber qué parte del código fue la última en modificar esa estructura.
También necesitamos un inicio para nuestra lista enlazada:
1
| |
Para nuestro malloc, queremos reusar el espacio libre si fuera posible, _alloc_ando espacio sólo cuando no podemos reusar el que ya tenemos. Dado que tenemos esta estructura de lista enlazada, buscar un bloque libre y devolverlo es casi trivial. Cuando tenemos un pedido de algún tamaño, iteramos nuestra lista buscando algún bloque libre con tamaño suficiente.
1 2 3 4 5 6 7 8 | |
Si no encontramos un bloque que nos sirva, le tenemos que pedir ese espacio al SO usando sbrk y lo agregamos al final de nuestra lista.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Como en nuestra implementación original, pedimos espacio usando sbrk, pero ahora le pedimos un poquito más de espacio para poder almacenar nuestra estructura, y además inicializamos los campos correctamente.
Ahora que tenemos las funciones auxiliares para ver si tenemos espacio libre y para pedirlo, nuestro malloc es simple. Si nuestro puntero base global es NULL, tenemos que pedir espacio y apuntar nuestro puntero base a ese nuevo bloque. Si no es NULL, buscamos si podemos reusar el espacio existente. Si podemos, lo hacemos, y si no pedimos espacio nuevo y lo usamos.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
Para quienes no se lleven mucho con C, devolvemos block+1 porque queremos devolver un puntero a la región siguiente a block_meta. Dado que block es un puntero del tipo struct block_meta, hacerle +1 incrementa la dirección en sizeof(struct block_meta) bytes.
Si sólo quisiéramos un malloc sin un free, podríamos haber usado nuestro malloc original, mucho más simple. Entonces, ¡escribamos nuestro free! Lo principal que free tiene que hacer es setear el campo ->free.
Como vamos a necesitar obtener la dirección de nuestro struct en varios lugares de nuestro código, definamos una función para ello:
1 2 3 | |
Ahora que lo tenemos, este es free:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Además de asignar ->free, es válido llamar a free con un puntero NULL, y por eso chequeamos por NULL. Como free no debería llamarse con cualquier dirección arbitraria o bloques que ya hayan sido liberados, asserteamos que esas cosas no pasen.
En realidad no es necesario assertear nada, pero suele ayudar a debuggear. De hecho, cuando escribí este código tuve un bug que hubiera resultado en corromper silenciosamente los datos si los asserts no hubieran estado ahí. En cambio, el código falló por los asserts, y debuggear el problema se volvió trivial.
Ahora que tenemos malloc y free, ¡podemos escribir programas usando nuestro propio gestor de memoria! Pero antes de meter nuestro gestor en programas ya existentes, necesitamos implementar un par de funciones comunes más: realloc y calloc. calloc es simplemente un malloc que inicializa la memoria en 0, así que arranquemos por realloc. realloc debería ajustar el tamaño de un bloque de memoria que obtuvimos a través de malloc, calloc o realloc.
El prototipo de realloc es:
1
| |
Si le pasamos un puntero a NULL, debería funcionar exactamente igual que malloc. Si le pasamos un puntero previamente malloceado, debería liberar espacio si el tamaño es menor al previo, y asignar más espacio y copiar los datos existentes si el tamaño es mayor que el anterior.
Los programas pueden seguir funcionando si no hiciéramos lo de achicar el bloque o liberarlo, pero sí necesitamos reservar más espacio cuando el tamaño se incrementa, así que empecemos con eso:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Y ahora calloc, que simplemente inicializa la memoria antes de devolver el puntero:
1 2 3 4 5 6 | |
Notemos que no chequea overflows en nelem * elsize, requerido por la especificación. Todo este código es simplemente lo mínimo necesario para que las cosas más o menos funcionen.
Y ahora que tenemos algo que más o menos funciona, usémoslo con los programas ya existentes (¡sin siquiera recompilarlos!).
Primero que nada, necesitamos compilar nuestro código. En Linux, algo como:
1
| |
debería funcionar.
-g agrega los símbolos de debug, para poder mirar nuestro código con gdb o lldb. -O0 va a ayudar a debuggear, evitando que en las optimizaciones se eliminen variables. -W -Wall -Wextra agrega warnings adicionales. -shared -fPIC nos permite linkear nuestro código dinámicamente, que es lo que nos permite usar nuestro código con binarios ya existentes.
En Mac usaríamos algo así:
1
| |
Notar que sbrk fue deprecado en las versiones recientes de OS X. Apple usa una definición poco ortodoxa de deprecado – algunas llamadas al sistema deprecadas directamente fallan. No probé esto en una Mac, así que puede que la implementación tenga fallas, o directamente no funcione en Mac.
Ahora, para que un binario use nuestro malloc en Linux, tenemos que setear la variable de entorno LD_PRELOAD. Si estás usando bash, podés hacerlo así:
1
| |
Si estás en Mac, el comando es:
1
| |
Si todo funciona, podés correr cualquier binario arbitrario y debería funcionar normalmente (excepto que será un poquito más lento).
1 2 | |
Si hubiera un bug, vas a ver algo así:
1 2 | |
Debuggeando
¡Hablemos de debugear! Si te es familiar el uso del debugger para poner breakpoints, inspeccionar la memoria y ejecutar paso a paso el código, podés saltear esta sección e ir directamente a los ejercicios.
Esta sección asume que podés instalar gdb en tu sistema. Si estás en Mac, probablemente quieras usar lldb y traducir los comandos apropiadamente. Como no tengo idea de qué bugs podés encontrarte, voy a introducir algunos bugs en el código para mostrarte cómo encontrarlos y resolverlos.
Primero, necesito poder correr gdb sin que genere un segmentation fault. Si ls segfaultea y tratamos de correr gdb ls, muy probablemente gdb vaya a segfaultear también. Podríamos escribir un wrapper para hacer esto, pero gdb también lo soporta. Si iniciamos gdb y después corremos set environment LD_PRELOAD=./malloc.so antes de correr el programa, LD_PRELOAD va a funcionar normalmente.
1 2 3 4 5 6 | |
Como esperábamos, tenemos un segfault. Podemos usar list para ver el código alrededor del error:
1 2 3 4 5 6 7 8 9 10 11 | |
Y podemos usar p (print) para ver qué está pasando con las variables:
1 2 3 4 | |
ptr vale 0, o sea, NULL, y esa es la causa del problema: nos olvidamos de chequear por NULL.
Ahora que encontramos eso, probemos con un bug un poco más complicado. Digamos que decidimos reemplazar nuestra estructura por:
1 2 3 4 5 6 7 | |
Y devolver block->data en lugar de block+1 en malloc, sin más cambios. Se parece bastante a lo que veníamos haciendo, sólo que ahora definimos un campo más que apunta al final de la estructura, y retornamos un puntero ahí.
Pero esto es lo que pasa si usamos nuestro nuevo malloc:
1 2 3 4 5 6 7 8 9 10 | |
Este no es tan lindo como el error anterior – podemos ver que uno de nuestros asserts falló, pero gdb nos deja tirados dentro de una función de printf, llamada cuando un assert falla. Pero esa función usa nuestro malloc buggeado ¡y revienta!
Lo que podemos hacer es inspeccionar ap para ver qué era lo que assert trataba de imprimir:
1 2 | |
Eso funcionaría bien. Podemos jugar un poquito hasta encontrar qué es lo que pretendía imprimir, y encontrar el error de ese modo. Otras formas hubieran sido implementar nuestro propio assert o usar los hooks correctos para prevenir que assert use nuestro malloc.
Pero, en este caso, nosotros sabemos que hay sólo unos pocos asserts en nuestro código: el de malloc, garantizando que no estemos usandolo en un programa multihilo, y los dos de free chequeando que no estemos liberando algo que no debiéramos. Miremos primero free, poniendo un breakpoint:
1 2 3 4 5 6 7 8 | |
Aún no asignamos block_ptr, pero si hacemos s un par de veces para avanzar hasta después de que fuera asignado, podemos ver que su valor es:
1 2 3 4 5 6 7 | |
Estoy usando p/x en vez de p para poder verlo en hexadecimal. El campo magic está en 0, que debería ser imposible para una estructura válida para liberar. ¿Puede que get_block_ptr esté devolviendo un offset incorrecto? Tenemos ptr disponible, así que podemos inspeccionar distintos offsets. Dado que es un void *, vamos a tener que castearlo para que gdb sepa cómo interpretar los resultados:
1 2 3 4 5 6 7 8 | |
Si miramos un poco la dirección que estamos usando, podemos ver que el offset correcto es 24 y no 32. Lo que está pasando es que la estructura tiene padding, es decir, está siendo alineada al tamaño de palabra del procesador. Entonces, sizeof(struct block_meta) es 32, incluso aunque el último campo válido esté en 24. Si queremos remover ese espacio extra, tenemos que arreglar get_block_ptr.
¡Y eso fue todo el debugging!
Ejercicios
Personalmente, estas cosas no me quedan hasta que no hago un par de ejercicios, así que voy a dejar algunos acá para quienes les interese.
- Se espera que
mallocdevuelva un puntero convenientemente alineado a cualquier tipo nativo. ¿Hace eso el nuestro? Si lo hace, ¿por qué? Si no, corregilo. Notá que “cualquier tipo nativo” es, básicamente, 8 bytes en C, dado que los tipos de SSE/AVX no son nativos. - Nuestro
mallocdesperdicia un montón de espacio si reusamos un bloque sin necesitar tanto tamaño. Implementá una función que lo divida en bloques que ocupen el espacio mínimo necesario. - Después de hacer
2, si llamamos amallocyfreemuchas veces con tamaños aleatorios, terminaremos con un montón de bloques pequeños que sólo se pueden reusar si pedimos cantidades pequeñas de memoria. Implementá un mecanismo que una bloques libres adyacentes para que varios bloques consecutivos se unan en uno solo. - ¡Encontrá bugs en el código existente! No lo testeé demasiado, así que tienen que haber bugs, por más que esto más o menos funcione.
Parte 2 en adelante
A continuación vamos a ver cómo hacer que esto sea más rápido y que sea thread safe.
Recursos
Leí este tutorial de Marwan Burelle antes de sentarme a escribir mi propia implementación, así que se parece bastante. Las principales diferencias son que mi versión es más simple, pero más vulnerable a la fragmentación de memoria. En términos de exposición, mi estilo es bastante más informal. Si querés algo más formal, el Dr. Burelle es tu camino a seguir.
Para saber más sobre cómo Linux maneja la memoria, mirá este post de Gustavo Duarte.
Para saber más sobre cómo funcionan las implementaciones reales de malloc, dlmalloc y tcmalloc son dos grandes lecturas. No leí el código de jemalloc, y escuché que es un poco más difícil de entender, pero es una de las implementaciónes de [malloc] de alta performance más usadas que hay.
Para ayuda debuggeando, Address Sanitizer la rompe. Y si querés escribir una versión thread-safe, Thread Sanitizer también es una gran herramienta.
Agradecimientos
Gracias a Gustavo Duarte por permitirme usar una de sus imágenes para ilustrar sbrk, a Ian Whitlock y Danielle Sucher por encontrar algunos typos, a Nathan Kurz por sus sugerencias sobre los recursos adicionales, y a “tedu” por encontrar un bug. Por favor, avisame si encontrás otros bugs en este post (tanto en el texto como en el código).